Creating and sharing tables in R can be tedious and time consuming. tablespan tries to make this process a bit easier by providing a “good enough” approach to tables. All you need is a single formula describing the table outline and tablespan will do the rest. Tables can be exported to HTML, Excel, LaTeX, and RTF.
Here is a basic example:
library(tablespan)library(dplyr)data("mtcars")summarized_table <- mtcars |>group_by(cyl, vs) |>summarise(N =n(),mean_hp =mean(hp),sd_hp =sd(hp),mean_wt =mean(wt),sd_wt =sd(wt))tbl <-tablespan(data = summarized_table,formula = Cylinder:cyl + Engine:vs ~ N + (`Horse Power`= Mean:mean_hp + SD:sd_hp) + (`Weight`= Mean:mean_wt + SD:sd_wt),title ="Motor Trend Car Road Tests",subtitle ="A table created with tablespan",footnote ="Data from the infamous mtcars data set.")as_gt(tbl = tbl)
Much of my research focuses on estimating large Structural Equation Models (SEMs). Combining regularization and SEM was first proposed by Jacobucci et al. (2016). With lessSEM (lessSEM estimates sparse SEM), I created a very flexible approach to regularizing SEMs. Compared to regsem and lslx - two alternatives to estimating regularized SEM, lessSEM provides the following functionality:
regsem
lslx
lessSEM
Model specification
based on lavaan
similar to lavaan
based on lavaan
Maximum likelihood estimation
Yes
Yes
Yes
Least squares estimation
No
Yes
Dev.
Categorical variables
No
Yes
No
Confidence Intervals
No
Yes
No
Missing Data
FIML
Auxiliary Variables
FIML
Multi-group models
No
Yes
Yes
Stability selection
Yes
No
Dev.
Mixed penalties
No
No
Yes
Equality constraints
Yes
No
Yes
Parameter transformations
diff_lasso
No
Yes
Definition variables
No
No
Yes
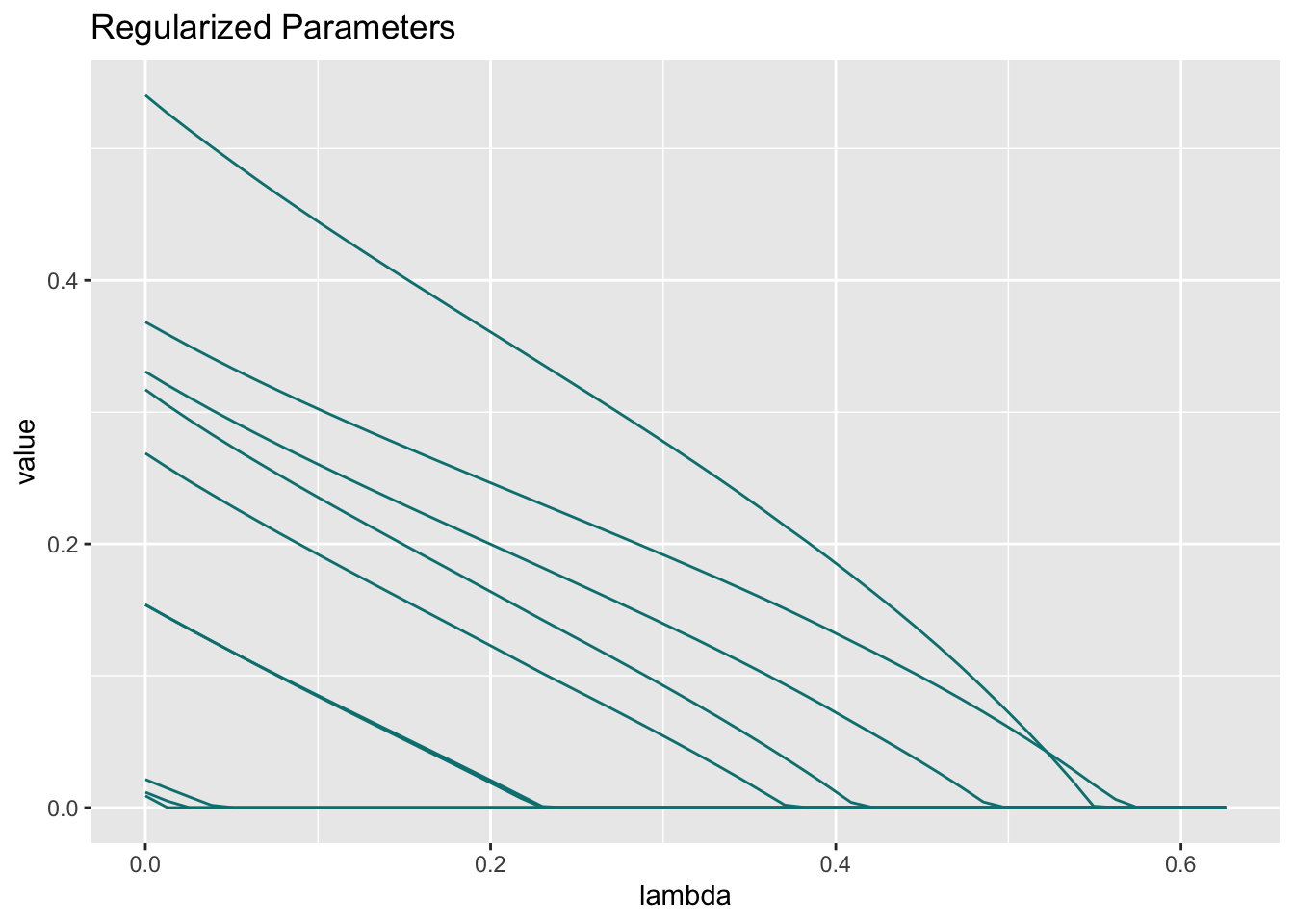
library(lessSEM)library(lavaan)# Identical to regsem, lessSEM builds on the lavaan# package for model specification. The first step# therefore is to implement the model in lavaan.dataset <-simulateExampleData()lavaanSyntax <-" f =~ l1*y1 + l2*y2 + l3*y3 + l4*y4 + l5*y5 + l6*y6 + l7*y7 + l8*y8 + l9*y9 + l10*y10 + l11*y11 + l12*y12 + l13*y13 + l14*y14 + l15*y15 f ~~ 1*f "lavaanModel <- lavaan::sem(lavaanSyntax,data = dataset,meanstructure =TRUE,std.lv =TRUE)# Regularization:lsem <-lasso(# pass the fitted lavaan modellavaanModel = lavaanModel,# names of the regularized parameters:regularized =c("l6", "l7", "l8", "l9", "l10","l11", "l12", "l13", "l14", "l15"),# in case of lasso and adaptive lasso, we can specify the number of lambda# values to use. lessSEM will automatically find lambda_max and fit# models for nLambda values between 0 and lambda_max. For the other# penalty functions, lambdas must be specified explicitlynLambdas =50)# use the plot-function to plot the regularized parameters:plot(lsem)
Structural Equation Models (SEMs) are extremely flexible. The R package OpenMx is one of the most versatile frameworks to implement SEMs. However, this versatility comes at a price: The model specification can be challenging for users new to SEM or new to R. mxsem unlocks some of the features that OpenMx provides with a lavaan-like syntax.
Here is an example, where we fit a SEM with definition variables:
library(mxsem)set.seed(9820)dataset <-simulate_moderated_nonlinear_factor_analysis(N =100)head(dataset, n =3)
Learning R is hard. During my teaching assignments at the Humboldt-Universität zu Berlin, I have contributed to the R Lernplattform that teaches R to psychology students (currently only in German).
lesstimate
lesstimate (lesstimate estimates sparse estimates) is a C++ header-only library that lets you combine statistical models such linear regression with state of the art penalty functions (e.g., lasso, elastic net, scad). With lesstimate you can add regularization and variable selection procedures to your existing modeling framework. It is currently used in lessSEM to regularize structural equation models.